
The Open Data Platform (ODP) is designed to aid in rapidly setting up a Hadoop environment and facilitate the ingestion of data to allow data analysis and visualization.
Data
The DATA Act Hackathon is aimed at leveraging data available from the following resources:
Hadoop Cluster
[Insert information about Hadoop cluster status page and the overall infrastructure being installed by Ambari]
Ingestion
The ODP project for data ingestion utilizes Apache NiFi. There are some example templates that demonstrate the ability of the platform to process incoming data as a REST API from spending-api.us or from CSV files. The example use case seeks to utilize geocoder to extract latitude/longitude coordinates based off zipcodes and transform the data into JSON to be indexed into ElasticSearch and then use Kibana as a visualization into that data.
The NiFi Templates are just guidelines and there are many default processors that come packaged with Nifi that allow the user to route and transform data into the system.
The github project is located:
https://github.boozallencsn.com/odp/odp-data-nifi
DATA Act Hackathon Example REST API Template
Access the NiFi instance that has been provisioned: http://{server}:8080/nifi/
This exposes an empty NiFi canvas where you can use the component toolbar to drag existing templates onto.
The template entitled Hackathon_Pull_Data_Webservice_GeoLocate_Elastic will pull in the following template:
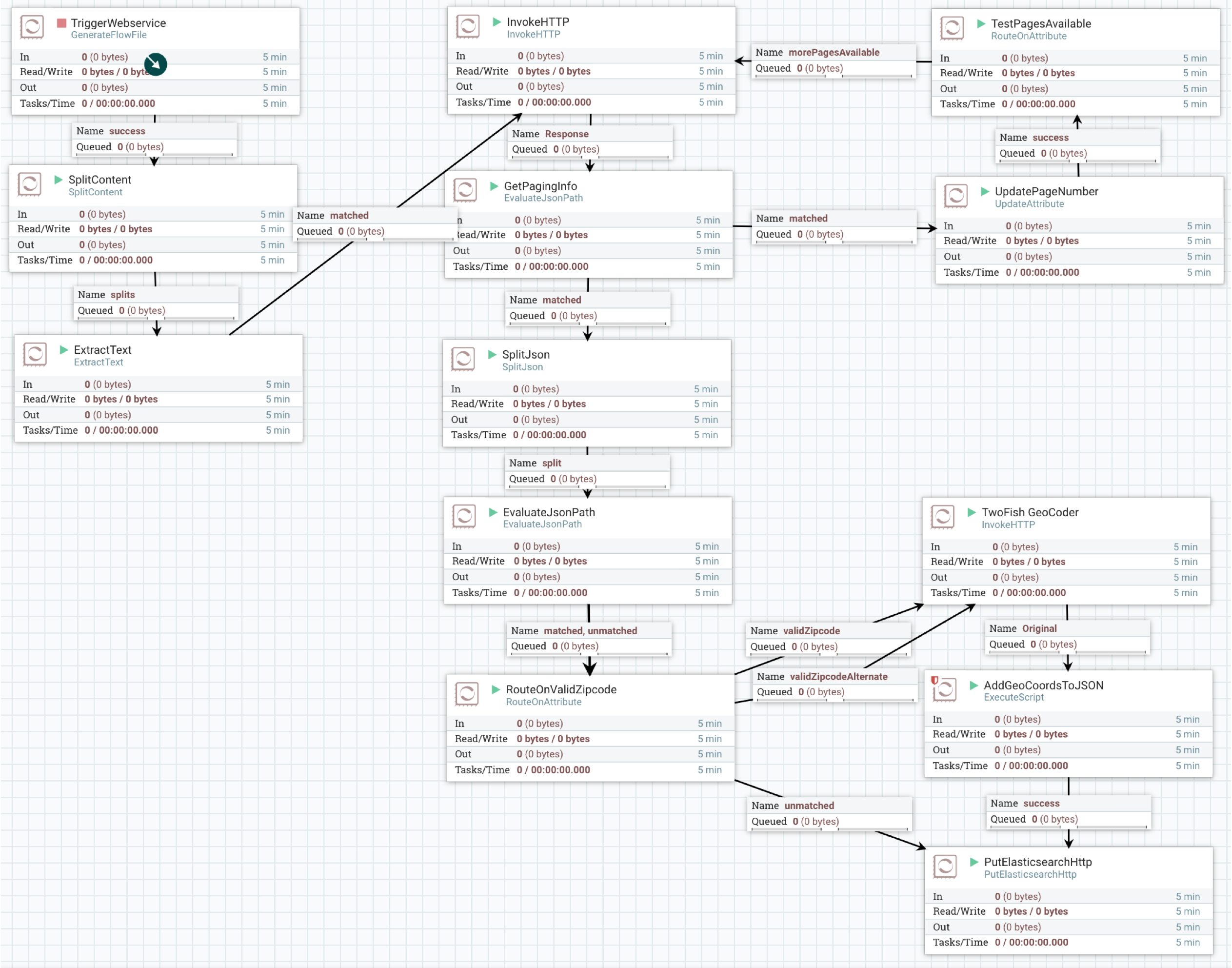
You can select individual components and start/stop them or right-click them to update their configuration or inspect data flowing through the Dataflow. This template will pull data from an API endpoint and page through the data. It will attempt to enhance the data by adding a geolocation based on zipcode and then ingest the data into ElasticSearch.
To trigger the webservice stop/start the TriggerWebservice processor. This template is designed to hit the endpoints for "awards" and "transactions."
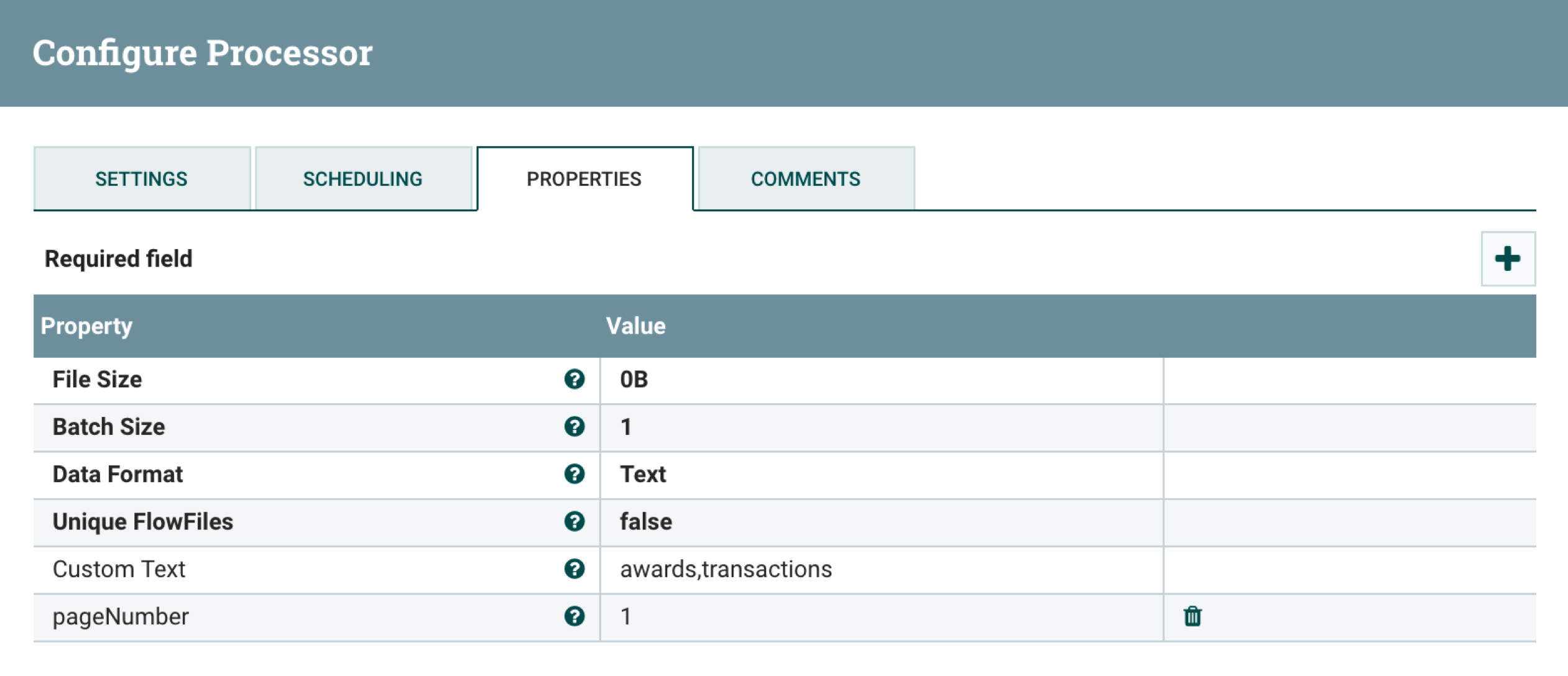
ElasticSearch can be accessed via the endpoint:
http://{server}:9200/
Kibana can be accessed via the endpoint:
http://{server}:5601/
Before ingesting/re-ingesting you can update the ElasticSearch mappings for your collection. Provided in the initial setup is a script that sets geo_points to aid in the kibana visualization. It is in the odp-nifi/scripts/setup_mappings_es.sh.

Connecting to kibana you can add visualizations on ingested fields via the visualizations and dashboard tab. Below is a simple example displaying the top 10 awarded agencies and their locations:

Zeppelin
Apache Zeppelin is another tool that allows data analytics and visualizations provided.
Flexibility
The templates shown here can be customized and other processors to feed data into any number of other solutions such as HDFS, HBase, Hive, Solr, etc. It is up to the user to determine the best way they want to load and analyze the data.